MySQL是如何设计的
MySQL
众所周知,MySQL是一个数据库管理系统,它在类别上属于关系型数据库。何为关系型数据库?从字面意思上,我们就可以大概猜到它应该是描述某种关系的数据库,而人类社会本质上是所有关系的总和。从现实世界延伸,人们需要在数字世界去描述这些关系,于是便有了关系型数据库。
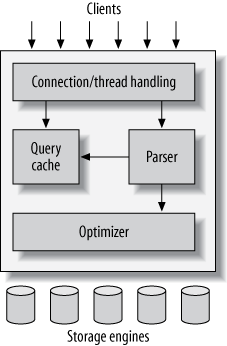
首先,我们先来看下 MySQL 服务器的逻辑架构图。
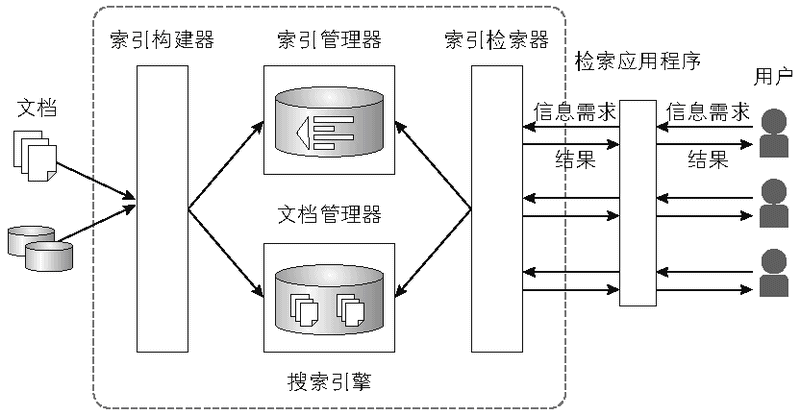
我们再来看下搜索引擎的架构图
存储引擎
MySQL 支持很多种存储引擎。除了最为大家熟知的MyISAM 和InnoDB,它还支持如下存储引擎。
- Archive 引擎
- Blackhole 引擎
- CSV 引擎
- Federated 引擎
- Memory 引擎
- Merge 引擎
- NDB 集群引擎
除了上面列出的。它还支持一些第三方存储引擎,这里不再多说。
InnoDB 目前是MySQL的默认事务型引擎,也是使用最广泛的存储引擎。那它有什么特点呢?
首先就是它支持事务,而且性能非常好,更有自动崩溃恢复特性。其次它采用MVCC(多版本并发控制)来支持高并发,并且实现了四个标准的隔离级别。其默认级别是REPEATABLE READ(可重复读),并且通过间隙锁(next-key locking)策略防止幻读出现。另外InnoDB表是基于聚簇索引建立的,聚簇索引对主键查询有很高的性能。
索引构建器
如果词典能够完整地加载到内存,那么所形成的二叉树的搜索效率将会非常高。特别是当二叉树处于平衡状态时,平均进行log2N次查找就能找到单词。
但是,如果词典无法完整地加载到内存,而必须存储到二级存储器上时,二叉树就未必是高效的数据结构了。HDD或SSD等二级存储器一般被称作“块设备”,由于它们是以块为单位进行输入输出的,所以即使只是读取块中1个字节的数据,也不得不对整个块进行输入输出操作。例如,假设我们用二叉查找树实现了含有 100 万个单词的词典,那么进行二分查找的话,平均需要 20 次查找,因此在最坏的情况下就需要加载 20 个块。也就是说,假设二级存储的加载性能为 5ms/ 块,那么在 1 次检索中,仅花费在二级存储输入输出上的时间就高达 100ms。
这里是这样计算的log2(1000000) 约等于20。
下面就让我们用 B+ 树来实现之前的包含了 100 万个单词的词典吧。假设有以下设定。
块大小:4KB 页大小:4KB 单词的平均大小:10 字节 页内偏移量的大小:2 字节 指向下一级结点的指针的大小:4 字节 由于单词的长度不是固定的,所以为了指示出每个单词在页中的保存位置,通常还要维护一个偏移量的数组。
基于这种假设,可以算出每个单词将占用页中 16 个字节的空间,因此每页中可以存放大约 250 个关键词(单词)8 。由于页中的每个单词都持有一个指向下级结点的指针,下级结点中存储的是按照词典顺序排
在该单词之前(后)的单词集合,所以可以推算出要存储 100 万个单词只需要 3 层结点就足够了(100 万< 250× 250×250 =约 1500 万)。也就是说,只要从二级存储中读取 3 个结点,就可以检索到任意的单词了。假设二级存储的加载性能还是 5ms/ 块,那么花在检索上的输入输出时间就是 15ms,这与花费在二叉查找树检索上的 100ms 的输入输出时间形成了鲜明的对比。
为了估算输入输出的次数,这里仅进行了非常粗略地计算。实际上每一页中还包含着用于管理该页信息的头部,而且如果一页中有 N 个单词的话,就还会有 N + 1 个指针。
Comments:
Email questions, comments, and corrections to hi@smartisan.dev.
Submissions may appear publicly on this website, unless requested otherwise in your email.